標準差
維基百科,自由的百科全書
標準差(英語:Standard Deviation),在機率統計中最常使用作為統計分佈程度(statistical dispersion)上的測量。標準差定義為變異數的算術平方根,反映組內個體間的離散程度。測量到分佈程度的結果,原則上具有兩種性質:
- 為非負數值;
- 與測量資料具有相同單位。
標準差的觀念是由卡爾·皮爾遜(Karl Pearson)引入到統計中。
目錄 |
闡述及應用
簡單來說,標準差是一組數值自平均值分散開來的程度的一種測量觀念。一個較大的標準差,代表大部分的數值和其平均值之間差異較大;一個較小的標準差,代表這些數值較接近平均值。
例如,兩組數的集合 {0, 5, 9, 14} 和 {5, 6, 8, 9} 其平均值都是 7 ,但第二個集合具有較小的標準差。
標準差可以當作不確定性的一種測量。例如在物理科學中,做重複性測量時,測量數值集合的標準差代表這些測量的精確度。當要決定測量值是否符合預測值,測量值的標準差佔有決定性重要角色:如果測量平均值與預測值相差太遠(同時與標準差數值做比較),則認為測量值與預測值互相矛盾。這很容易理解,因為如果測量值都落在一定數值範圍之外,可以合理推論預測值是否正確。
標準差應用於投資上,可作為量度回報穩定性的指標。標準差數值越大,代表回報遠離過去平均數值,回報較不穩定故風險越高。相反,標準差數值越小,代表回報較為穩定,風險亦較小。
母體的標準差
基本定義
簡化計算公式
上述公式可以如下代換而簡化:
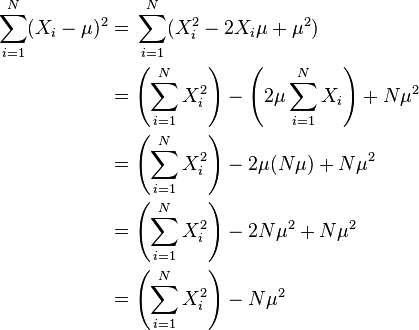
所以:
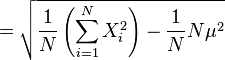
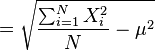
根號裡面,亦即變異數( )的簡易口訣為:「平方的平均」減去「平均的平方」。
)的簡易口訣為:「平方的平均」減去「平均的平方」。
)的簡易口訣為:「平方的平均」減去「平均的平方」。母體為隨機變數
一隨機變量  的標準差定義為:
的標準差定義為:
的標準差定義為:
 具有相同機率,則可用上述公式計算標準差。
具有相同機率,則可用上述公式計算標準差。離散隨機變數的標準差
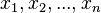 構成的
構成的![\sigma = \sqrt{\frac{1}{N}\left[(x_1-\mu)^2 + (x_2-\mu)^2 + \cdots + (x_N - \mu)^2\right]}](http://upload.wikimedia.org/math/5/f/d/5fd5ad66a1ae1ee408268b16d163432d.png) ,其中
,其中 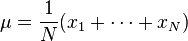
換成用 來寫,就成為:
來寫,就成為:
來寫,就成為: ,其中
,其中
目前為止,與母體標準差的基本公式一致。
然而若每個 可以有不同機率
可以有不同機率 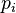 ,則的標準差定義為:
,則的標準差定義為:
可以有不同機率 ,則的標準差定義為: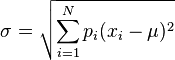 ,其中
,其中 
連續隨機變數的標準差
 的
的
其中
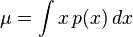
標準差的特殊性質
對於常數  和隨機變數 和
和隨機變數 和  :
:
和隨機變數 和 :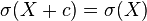
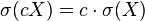

- 其中:
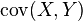 表示隨機變數 和 的共變異數。
表示隨機變數 和 的共變異數。
- 其中:
樣本的標準差
在真實世界中,找到一個母體的真實的標準差是不現實的。大多數情況下,母體標準差是通過隨機抽取一定量的樣本並計算樣本標準差估計的。
從一大組數值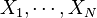 當中取出一樣本數值組合
當中取出一樣本數值組合  ,常定義其樣本標準差:
,常定義其樣本標準差:
當中取出一樣本數值組合 ,常定義其樣本標準差:
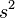 是對母體
是對母體 中分母為
中分母為 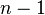 (相較於母體
(相較於母體 中的分母為
中的分母為 的
的 。
。範例
這裡示範如何計算一組數的標準差。例如一群孩童年齡的數值為 { 5, 6, 8, 9 } :
- 第一步,計算平均值
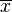 ︰
︰

- 當
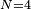 (因為集合裏有 4 個數),分別設為:
(因為集合裏有 4 個數),分別設為:
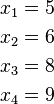
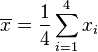
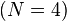
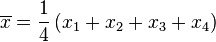
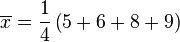
 (此為平均值)
(此為平均值)
- 第二步,計算標準差
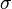 ︰
︰
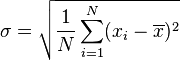

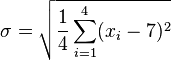
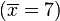
![\sigma = \sqrt{\frac{1}{4} \left [ (x_1 - 7)^2 + (x_2 - 7)^2 + (x_3 - 7)^2 + (x_4 - 7)^2 \right ] }](http://upload.wikimedia.org/math/1/b/3/1b3ee6d89f69664070242d56103f30b0.png)
![\sigma = \sqrt{\frac{1}{4} \left [ (5 - 7)^2 + (6 - 7)^2 + (8 - 7)^2 + (9 - 7)^2 \right ] }](http://upload.wikimedia.org/math/6/2/c/62c241b9f368cfa8d1d37b0a53950a55.png)



 (此為標準差)
(此為標準差)
常態分佈的規則

在實際應用上,常考慮一組數據具有近似於常態分佈的機率分佈。若其假設正確,則約 68% 數值分佈在距離平均值有 1 個標準差之內的範圍,約 95% 數值分佈在距離平均值有 2 個標準差之內的範圍,以及約99.7% 數值分佈在距離平均值有 3 個標準差之內的範圍。稱為「68-95-99.7 法則」。
標準差與平均值之間的關係
一組數據的平均值及標準差常常同時作為參考的依據。從某種意義上說,如果用平均值來考量數值的中心的話,則標準差也就是對統計的分散度的一個「自然」的測度。因為由平均值所得的標準差要小於到其他任何一個點的標準差。較確切的敘述為:設 為實數,定義函數
為實數,定義函數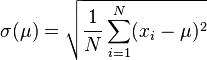
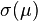 在下面情況下具有唯一最小值:
在下面情況下具有唯一最小值:
幾何學解釋
從幾何學的角度出發,標準差可以理解為一個從  維空間的一個點到一條直線的距離的函數。舉一個簡單的例子,一組數據中有3個值,
維空間的一個點到一條直線的距離的函數。舉一個簡單的例子,一組數據中有3個值,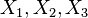 。它們可以在3維空間中確定一個點
。它們可以在3維空間中確定一個點  。想像一條通過原點的直線
。想像一條通過原點的直線  。如果這組數據中的3個值都相等,則點
。如果這組數據中的3個值都相等,則點  就是直線
就是直線  上的一個點, 到 的距離為0, 所以標準差也為0。若這3個值不都相等,過點 作垂線
上的一個點, 到 的距離為0, 所以標準差也為0。若這3個值不都相等,過點 作垂線  垂直於 , 交 於點
垂直於 , 交 於點 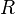 ,則 的坐標為這3個值的平均數:
,則 的坐標為這3個值的平均數:
維空間的一個點到一條直線的距離的函數。舉一個簡單的例子,一組數據中有3個值,。它們可以在3維空間中確定一個點 。想像一條通過原點的直線 。如果這組數據中的3個值都相等,則點 就是直線 上的一個點, 到 的距離為0, 所以標準差也為0。若這3個值不都相等,過點 作垂線 垂直於 , 交 於點 ,則 的坐標為這3個值的平均數: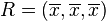
運用一些代數知識,不難發現點 與點 之間的距離(也就是點 到直線 的距離)是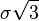 。在 維空間中,這個規律同樣適用,把
。在 維空間中,這個規律同樣適用,把 換成 就可以了。
換成 就可以了。
與點 之間的距離(也就是點 到直線 的距離)是。在 維空間中,這個規律同樣適用,把換成 就可以了。外部連結
- Standard Deviation Calculator標準差計算器(英文)
沒有留言:
張貼留言